作者:gaoxing332844731 | 来源:互联网 | 2024-11-29 13:37
前言:本文由编程笔记小编整理,旨在详细介绍大数据SQL优化中的数据倾斜问题及其解决方案,希望能为读者提供有价值的参考。
1. 数据倾斜概述
数据倾斜是指在大数据计算任务中,某个处理任务的进程(通常是一个JVM进程)被分配到过多的任务量,导致任务运行时间过长甚至失败,从而影响整个任务的执行效率。在HiveSQL任务中,可能会观察到map或reduce的进度长时间停留在99%;而在SparkSQL中,则可能表现为某个stage中的任务数量长时间保持在1或2个。如果任务进度信息长时间没有变化,通常意味着出现了数据倾斜。需要注意的是,有时SparkSQL任务显示有1到2个任务在运行,但进度信息不再刷新,这通常是在进行最后阶段的文件操作,并不是数据倾斜,但这可能表明存在小文件问题。
数据倾斜可以细分为以下四类:
1)读倾斜:某个map(HiveSQL)或task(SparkSQL)在读取数据阶段长时间无法完成,通常是因为文件分块过大或数据异常。这种场景相对较少见。
2)算倾斜:在需要排序(如开窗函数或非广播关联)或聚合操作时,同一key(字段或表达式组合)的处理耗时过长。这是最常见的倾斜类型,且情况较为复杂。
3)写倾斜:某个操作需要输出大量数据,例如关联后数据膨胀或某些操作(如limit)只能由一个task完成。
4)文件操作倾斜:数据生成在临时文件夹后,由于文件数量巨大,重命名和移动操作非常耗时。这通常发生在动态分区导致的小文件问题上。目前,国内和印度区域已通过小文件合并解决了这一问题,但在新加坡仍需关注。
2. 数据倾斜的原因
大数据计算依赖于分布式系统,需要将计算任务和数据分发到集群中的各个节点执行,并最终汇总到少数节点进行聚合操作,以及将数据写入HDFS/S3等分布式存储系统。这一过程虽然设计用于应对大多数情况,但仍存在以下几点不足:
1)业务数据分布规律难以预测,系统无法提前知道某个表的字段取值分布是否均匀。
2)计算结果数量难以预测,例如两表关联的结果或对字段值进行split等操作后的结果数量无法提前预知。
3)某些操作只能由单一节点执行,如排序、Limit、count distinct、全局聚合等,这些操作通常会安排到一个节点来执行。
上述特点导致单节点处理的数据量可能极大,从而引发数据倾斜。然而,随着技术的发展,越来越多的优化措施已被提出,未来业务人员可能会减少因数据倾斜带来的困扰。
3. 解决案例
以下案例主要基于SparkSQL,展示了如何解决不同类型的数据倾斜问题。
3.1 事实表关联事实表数据膨胀
业务中有时需要将事实表与事实表进行关联,导致某些key的输出数据量极大,造成数据膨胀和计算倾斜。例如,两个表通过option_id关联,部分key的关联结果可达数十亿行,严重倾斜。解决这一问题的关键在于减少单个task处理的数据量。通过使用collect_set/collect_list等聚合函数,可以将数据收拢,减少行数,再通过explode + lateral view的方式展开,最终恢复到用户期望的明细结果。具体代码示例如下:
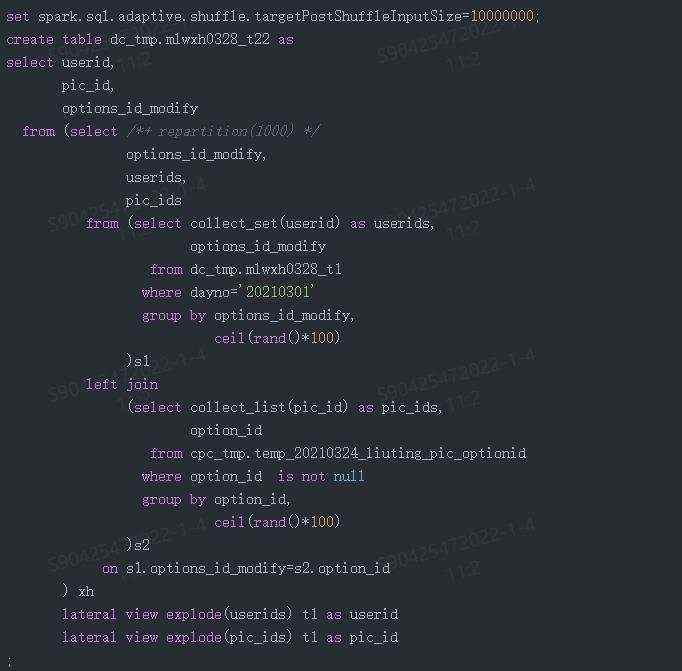
代码中的关键点包括:
• repartition(1000):将上一阶段关联后的结果分成1000份,以减少单个任务处理的数据量。
• ceil(rand()*N):将一个key分成最多N行,限制最终按key关联后生成的行数。
• spark.sql.files.maxPartitionBytes:控制单个任务处理的数据量,进一步拆分任务。
通过上述优化,任务在20分钟内完成,生成了近800亿行的数据,其中包括19个超十亿行的key。
3.2 避免排序
排序操作在大数据处理中开销巨大,尤其是在数据量较大的情况下。以下是两个通过改写代码避免排序的案例:
1)用max函数替换排序:
业务需求是从1200亿行数据中抽取约1万条样本数据。原SQL通过排序获取每组数据中size最大的记录,但由于某些key的数据量极大,导致任务失败。优化后的思路是通过max函数获取每个key的最大值,再与原表关联,提取最大值对应的记录。具体代码如下:
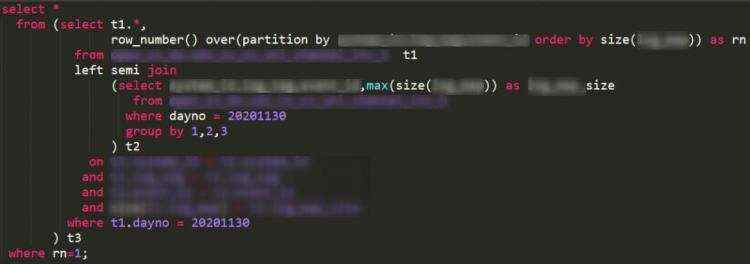
代码中的关键点包括:
• semi join:左表匹配右表,一旦匹配成功即停止查找,提高效率。
• row_number:对结果进行开窗,取第一条记录。
2)用分位函数替换排序:
业务需求是对数据进行分档打标。原SQL通过全局排序获取每个记录的位置,但由于数据量过大,任务失败。优化后的思路是使用分位数函数,计算数据必须大于或等于某个值才能处于某个位置,从而避免全局排序。具体代码如下:
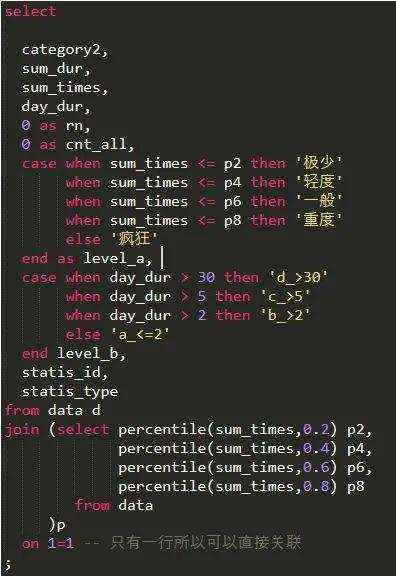
通过上述优化,任务执行时间减少了约87%。
3.3 写倾斜的避免
在动态分区场景下,很难预测每个分区将要输出的数据量。如果分配的task数量固定,可能导致某些分区的任务量过大,影响任务执行效率。解决方法是通过distribute by + case when表达式,让引擎根据不同的分区分配不同数量的任务。具体代码示例如下:

3.4 非法值过滤
在处理大数据任务时,有时会遇到非法值导致的倾斜问题。例如,在一个任务中,发现某个字段的空值数量巨大,导致任务运行时间不断增加,最终失败。通过与业务人员沟通,确认空值无意义,将其过滤掉后,任务在30分钟内完成,耗时下降约90%。如果倾斜值有意义,通常需要将其单独处理,再与其他非倾斜数据合并。
4. 结语
数据倾斜是大数据处理中的常见问题,本文通过多个实际案例,详细介绍了如何识别和解决不同类型的数据倾斜问题。未来,我们将开发更多的诊断和优化工具,帮助用户更有效地应对数据倾斜。
作者简介
Luckyfish,OPPO大数据服务质量负责人,主要负责大数据平台支持维护及服务质量保证工作,曾供职于京东科技,有丰富的任务开发和性能优化经验,同时对产品体验和成本优化有较多兴趣和经验。








 京公网安备 11010802041100号
京公网安备 11010802041100号